




Machine learning uses several different ways in automatic document classification, each with its own strengths and weaknesses. The three most common approaches are supervised, unsupervised, and semi-supervised learning.
Supervised Document Classification
Supervised learning requires a labeled training dataset, where documents are paired with their correct category. By analyzing these labeled examples, the model learns to identify patterns and classify new, unseen documents.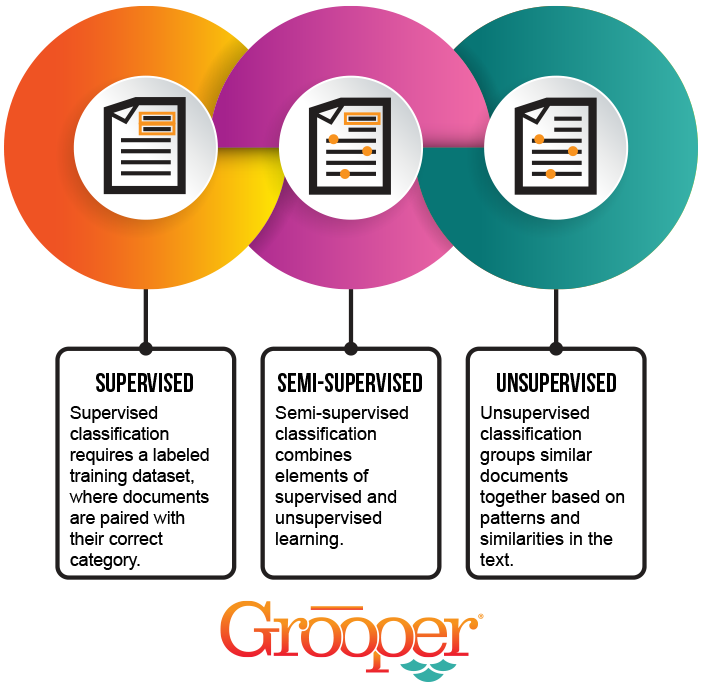
Positives of Supervised Document Classification:
- Potentially higher accuracy than unsupervised methods.
- Easier to evaluate performance.
Negatives of Supervised Document Classification:
- Requires a significant amount of labeled training data, which can be time-consuming and expensive to acquire.
Unsupervised Document Classification
Unsupervised methods, on the other hand, does not rely on labeled data. Instead, it groups similar documents together based on inherent patterns and similarities within the text. Techniques like clustering and topic modeling are commonly used for this purpose.
Positives of Unsupervised Document Classification:
- Does not require a labeled training dataset.
- Can be faster and more cost-effective than supervised methods.
Negatives of Unsupervised Document Classification:
- More challenging to evaluate performance.
- May not always produce meaningful or accurate classifications.
Semi-Supervised Document Classification
Semi-supervised learning combines elements of both supervised and unsupervised learning. It leverages a small amount of labeled data along with a larger amount of unlabeled data to improve classification accuracy.
This approach can be particularly useful when labeled data is scarce or expensive to obtain.
Positives of Semi-Supervised Document Classification:
- Can improve the accuracy of both supervised and unsupervised methods.
- Requires less labeled training data than fully supervised methods.
Disadvantages of Semi-Supervised Document Classification:
- More complex to implement than purely supervised or unsupervised methods.
- May not always outperform fully supervised methods.
How Does Document Classification Work?
Document classification organizes documents into different categories, either manually or through automation. When classification is automated, it uses machine learning (ML) algorithms and natural language processing (NLP).
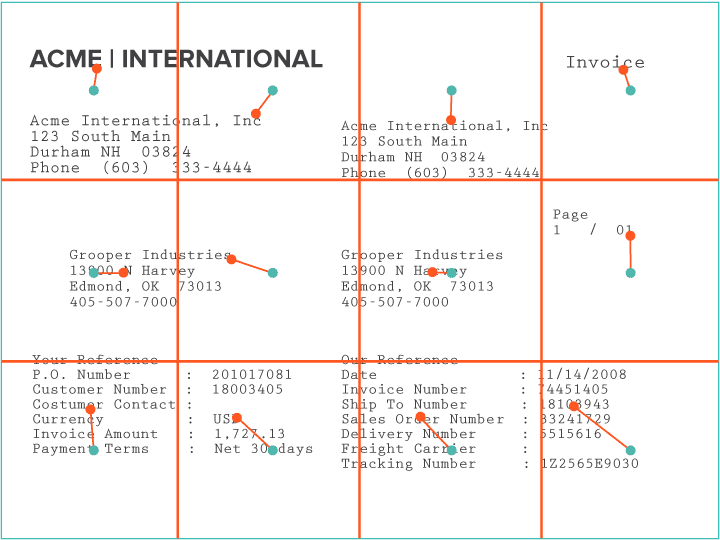
The types of documents that can be classified include text documents, scanned image documents, electronic files, etc.
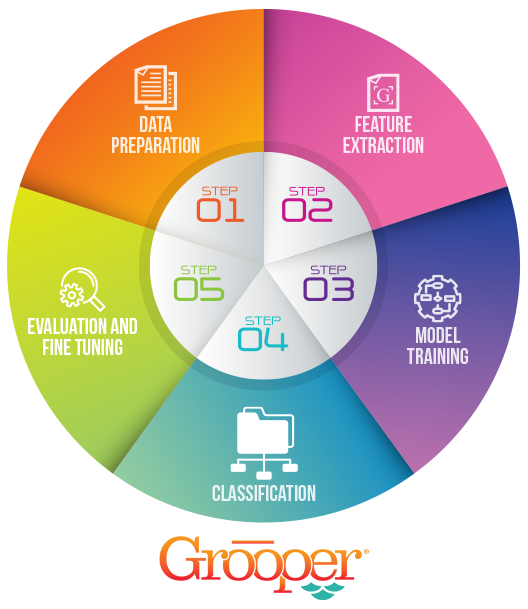
Here is each step of how document classification software works to organize your documents:
- Dataset Preparation:
- Data Collection: Gather a diverse and representative dataset of documents relevant to your classification task. A dataset generally needs to be large enough to lead to good model performance.
- Data Preprocessing: Clean and prepare the document image by removing noise or tokenize text. Then convert it into a suitable format for machine learning algorithms.

- Feature Extraction:
- Identify Key Features: Document classification software then extracts relevant features from the documents, like words, phrases, or other linguistic elements that characterize the content.
- Vectorization: Convert the extracted features into numerical representations (vectors) that can be understood by machine learning algorithms.
- Model Training:
- Choose a Model: Select a suitable machine learning algorithm based on the nature of the data and classification task. Options include: Naive Bayes, Support Vector Machines, or Random Forest.
- Train the Model: Train the chosen model (whether it’s supervised, unsupervised, or semi-supervised) using the prepared dataset. The model learns to associate specific features with corresponding document categories.
- Classification:
- Input New Document: Feed a new, unseen document into the trained model of the document classification solution.
- Predict Category: The model analyzes the document’s features and assigns the most likely category or label based on the learned patterns.
- Evaluation and Fine Tuning:
- Assess Performance: You can then evaluate the model’s accuracy in your classification software using metrics like precision, recall, F1-score, and confusion matrices.
- Iterative Improvement Through Fine Tuning: With software like Grooper, you can continuously improve the model by adjusting its parameters, retraining with more data, or exploring different algorithms to optimize performance.
By following these steps, you can effectively classify documents and automate tasks like sorting emails, categorizing news articles, or organizing research papers.
What are the Benefits of Document Classification?
Time and Cost Savings
 Document classification software automates the process of manually organizing and analyzing vast quantities of documents. This powerful AI-driven solution significantly reduces the time and effort typically spent on manual sorting and searching. By automatically categorizing documents, businesses can:
Document classification software automates the process of manually organizing and analyzing vast quantities of documents. This powerful AI-driven solution significantly reduces the time and effort typically spent on manual sorting and searching. By automatically categorizing documents, businesses can:
- Save valuable time: Free up employees to focus on more strategic tasks.
- Improve efficiency: Streamline workflows and boost overall productivity.
With automated document classification, your business can unlock the full potential of your data and achieve greater efficiency.
Elevate Customer Satisfaction with Automated Document Classification
 Document classification solutions empower businesses to significantly enhance customer satisfaction by streamlining customer service operations and expediting issue resolution.
Document classification solutions empower businesses to significantly enhance customer satisfaction by streamlining customer service operations and expediting issue resolution.
By automatically categorizing customer inquiries, businesses can:
- Quicken response times: Swiftly route issues to the correct department or agent.
- Reduce wait times: Minimize customer wait times and frustration.
- Improve accuracy: Ensure that customer feedback is addressed with precision.
- Personalize experiences: Tailor responses to specific customer needs.
Ultimately, automated document classification leads to happier customers and stronger customer relationships.